RAG Considerations
Introduction
RAG is a great way to focus Certara AI on specific information, allowing it to answer more accurately. However, this doesn't mean RAG is the best for every use case. This guide will go over how to determine if you should use RAG or not.
RAG VS RAG-Skip
Being able to distinguish between these two options is the first step to deciding how to implement your AI workflow. In Certara AI, RAG indicates retrieval of text chunks that are related to the prompt. These retrieved chunks then get attached to the prompt before being forwarded to the LLM. RAG-Skip indicates that ALL text from the document will be attached to the prompt.
Considerations
Here is a general list of things to consider.
- Are your prompts asking for specific information or are you asking generalized questions?
- What context length is the model you are using set at?
- How are you embedding the sources?
- Are you going to be prompting against tables, text documents, or both?
- How many sources are you are you prompting against and how large are they?
Lets go over these in more detail below.
Generalized or Specific Prompting
Part of determining if RAG is going to be useful is understanding what sort of information you want to pull from the document. For example, if you have a study that you want to pull information from various sections, doing RAG-Skip is best, because the model will need a majority of the study text in order to accurately respond. If you want to pull specific information like how the cohort was assembled or what the conclusion of the study was, RAG is going to do well, because it will only give the model context for the specific thing you are asking for.
Model Context Length
Models have specific context lengths which determines how many tokens the prompt can contain to prevent the model from presenting an error. You can find out more about how context length is set in your Layar instance here: Setting Context Length
Top of the line models like, Llama 4.0 have large context lengths. However, you may not have the hardware required to utilize the full context length.
Context length will determine your RAG/RAG-Skip use cases. If your documents are very large, you may not be able to skip RAG, because the amount of text can't fit in the context window. In these cases, RAG will help because it cuts down on the amount of tokens given to the model. Additionally, making smaller sets in Layar can allow you to prompt against data sets to match your context length.
Context Length ErrorsWhen disabling RAG, you may get errors saying the context length is exceeded. In these cases, RAG will need to be enabled to ensure context length is not exceeded.
Embedding Decisions
Layar allows you to control embedding via the GUI and API. Depending on the which you are embedding, you will have various options to choose from. Lets go over those below.
Documents
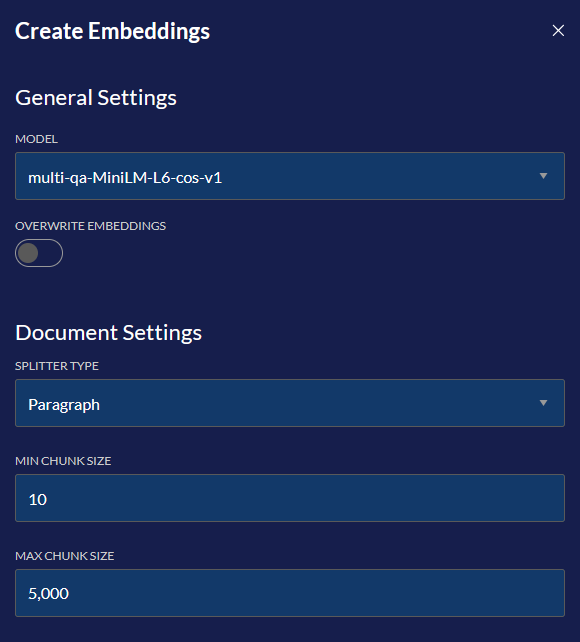
Model
Determines what embedding model is going to be used. This isn't as relevant for GUI workflows because the default model is the only one that will be used in Composer. However, if you are using the API, experimenting with embedding models is a good idea since some may be better then others for your workflow.
Splitter Type
Determines how the text will be embedded. If you are planning to ask more generalized questions against the source, Paragraph may be better then Sentence. If you are planning to ask more specific questions, Sentence may be better.
Min Chunk Size
Determines how small a chunk can be. Leaving this too small may cause irrelevant chunks to be given to model, skewing accuracy of the response.
Max Chunk Size
Determines how large a chunk can be. If the chunk is too large, it may not actually give any benefit compared to RAG-less workflows, since a large part of the document may be in a single chunk.
Take Away
It's best to start with defaults when doing text document embedding. See how defaults work for your use case then change from there. The biggest thing to consider is if you want chunks with a paragraph split or sentence split, since this will decide how much context is given to the model.
Tables
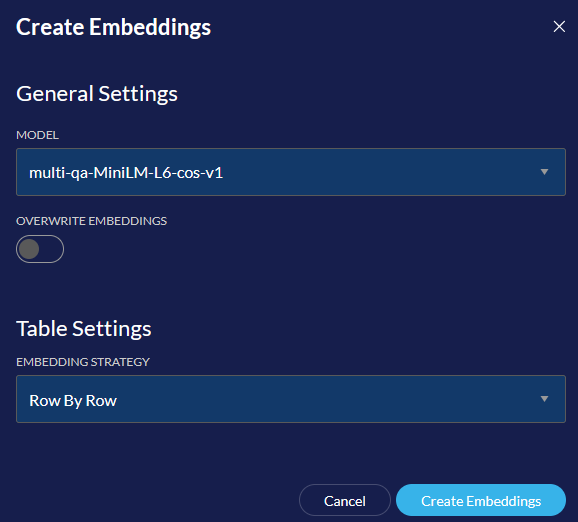
Embedding Strategy
This determines how the data from a table is split into chunks.
Row By Row turns each row of data into a chunk. These chunks include the column headers and the values for each cell in that row. When performing RAG, it will find each relevant row that has information related to your prompt.
Whole Table turns the whole table into a chunk. This chunk includes the whole table including the column headers.
Take Away
Determining if you should use Row By Row or Whole Table comes down to what you are trying to pull out of these tables. If you are looking to get details that will require looking at the entire table, Whole Table is better. If you need to pull out specific information use Row By Row.
Data Set Contents
It's important to understand what is in the sets you will ask questions against. If you have a set that is a mix of tables and text documents, and you are looking to pull specific details from the sources, RAG is a good idea, since it will drastically cut down on the amount of context that will be given to the model. Sending chunks that contain both table and text document table will negatively effect accuracy. If you are interested in pulling more generalized data from a mixed set, it's best to skip RAG because you will want more context given to the model.
Context LengthIt's always important to consider how much information will be given back to the model. If you have a very large set and decide to skip RAG, context length of the model could be exceeded. In cases where this occurs, you will get a message detailing the context length has been exceeded and RAG will be used.
Source Size
Similar to data set contents, understanding how large your documents are will effect your RAG use cases. If you have a lot of large studies with disparate topics in a data set, this may result in inaccurate responses. Considering how you should organize the data in sets should be high priority BEFORE engineering prompts. For example, you may have studies focusing on IBS and Chrons. Even though they both focus on gastrointestinal issues, doing RAG against a set with both of these topics may result accuracy issues. It would be best to create two separate sets to hold the studies and then doing RAG against each set in order to get more accurate results.
Examples
Here are some general examples of when you would use RAG or not.
Mandatory RAG
If the document is large enough, all of the text will exceed context length, resulting in an error. In these cases you will need to use RAG to ensure the prompt doesn't go over context length.
Optional RAG
If the information you need from a document is very specific, RAG may be a better option even though the entire document doesn't exceed context length. In these cases, it's best to use RAG if the prompt returns an accurate response. Using RAG will improve the speed of inference, allowing for higher throughput.
Optional RAG-Skip
If you require a mixture of information from the document, RAG may not be able to pull all the necessary text chunks to provide an accurate response. In these cases using RAG-Skip will send all text from the document with the prompt. This will ensure the AI is given full context in order to provide a correct response.
Mandatory RAG-Skip
There may not be a case where RAG-Skip is always needed. It's best to test prompts using both RAG-Skip and RAG in order to see which one provides the best answer. However, if both methods work, RAG will result in faster response times.
Updated 9 months ago